对于大多在应用层面写MapReduce job的童鞋,不论写streaming/pipes,还是java,通常认为hadoop MR计算框架对数据排序发生在reduce阶段,这也是应用层面最直观易见的,实际在map阶段也有排序操作,笔者以此文分别分析map和reduce两个阶段的排序,处理大数据时所采用的排序算法,以及排序所起到的作用。
本文以facebook开源版本hadoop20的基础代码做参考,facebook该版本源于apache社区的0.20.X版本(第一代hadoop 1.0),提起MR不得不先祭出下面的经典图,展示了一个MR job从原始输入、map阶段、shuffle、reduce阶段、最终输出的数据流向基本过程: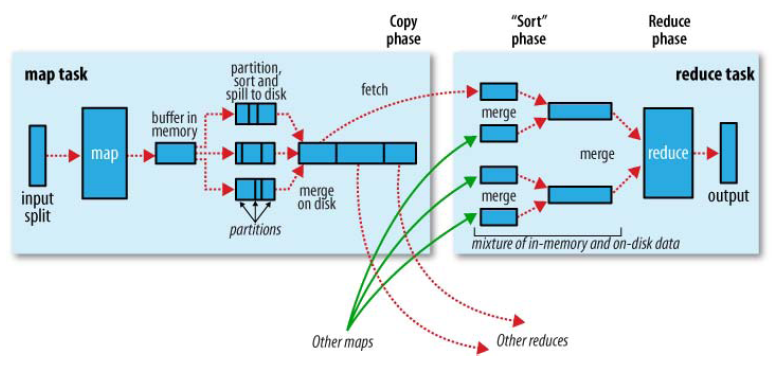
从图中也可以看到在map task数据溢写本地磁盘会有sort操作,reduce task拉取每个map对应partition的产出即shuffle也会会经过再次sort,将数据送给reduce实际操作。使用MR的童鞋都知道reduce阶段接收的数据输入必然是同一partiiton key有序的,因此shuffle数据后必然要经过排序才能保证计算框架的该特性,那为神马还需要在map阶段进行排序呢?通常我们使用hadoop MR处理海量数据计算分析,map的产出必然很大,如果没有map阶段的排序直接将数据shuffle给reduce操作,不论采取什么排序算法,reduce过程的排序必然比较耗时低效,产生性能瓶颈,而且shuffle本身就很耗时(大多情况下网络IO),大多集群的reduce槽位相比map资源也比较稀缺,鉴于此,shuffle获取的全部数据将是局部有序,在此基础上选择合适的排序算法将加快reduce的执行。
下面我们先从map阶段进行分析,map接受inputsplit输入数据,处理结果暂存至内存缓冲区,当缓冲区使用率达到一定阈值后,再对缓冲区的数据进行一次排序并将结果以支持行压缩的IFile出存储格式写入磁盘文件,当该task全部数据处理完毕后,会对磁盘上的对应所有文件进行一次合并,将这些文件合并成一个大的有序文件。
再看 reduce阶段,首先会从每个map task上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则放到磁盘上否则放到内存里。如果磁盘上文件数目达到一定阈值,则进行一次合并以生成一个更大的文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据写到磁盘上。当所有数据拷贝完成后,该task统一对内存和磁盘上的所有数据进行一次合并。
在map和reduce阶段运行过程中,缓冲区数据排序使用了优化过的快速排序算法,优化点包括:
1> 将序列首尾和中间元素的中位数作为枢轴
2> 子序列划分采用从左右两端进行扫描至符合条件交换
3> 每次划分子序列时将与枢轴相同的元素集中存放到中间位置,不参与后续递归
4> 子序列中元素数小于13时直接使用插入排序,不再递归
以上几点与STL sort是基本一致的,不过STL sort对于递归层次过深时会改用堆排序。
源码中相应的类为org.apache.hadoop.util.QuickSort。
map阶段中IFle文件合并采用了多轮递归合并排序,每轮选取最小的前io.sort.factor个文件进行合并,并将产生的文件重新加入待合并列表,直至剩下的文件数目小于io.sort.factor个。在每一轮合并过程中采用了小顶堆实现,可将文件合并过程看作一个不断建堆的过程。实质使用了基于极小堆实现的优先级队列。
源码中相应类为org.apache.hadoop.mapred.Merger。
reduce阶段中,shuffle从各个map task上远程拷贝一片数据,并针对某一片数据,如果大小超过一定阈值则写到磁盘上,否则直接写到内存里;在远程拷贝数据的同时,该task启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。由于map task的产出已经是局部有序,只需对所有数据进行一次归并排序即可。为提高效率,实际将merge sort与reduce调用并行化,该过程也是基于小顶堆。
源码中相应类为org.apache.hadoop.mapred.ReduceCopier。
refer:
1. 《Hadoop技术内幕-深入解析MapReduce架构设计与实现原理》